
Origine
Git a été inventé et développé par Linus Torvalds en 2005. Il s’agit un logiciel libre et gratuit permettant aux développeurs de gérer les changements apportés au code au fil du temps. Linus Torvalds c’est aussi le petit génie qui est à l’origine du noyau Linux qu’il a commencé en 1991, donc bien avant Git.
Linux c’est un projet plutôt conséquent et il a donc dû nécessiter l’usage d’un outil de gestion de version. Cet outil, à l’époque, c’est BitKeeper. Le problème de BitKeeper, c’est qu’il s’agit d’un logiciel propriétaire et que toute la communauté qui gravite autour de Linux, elle n’aime pas vraiment les logiciels propriétaires. Alors que BitKeeper n’est déjà pas totalement apprécié par la communauté Linux, ils vont faire une annonce qui va déclencher la colère de toute cette communauté et surtout de Linus Torvalds. Ils vont cesser, du jour au lendemain, d’être gratuit. C’est à ce moment précis que Linus Torvalds décide de développer lui même son propre système de gestion de version du code source et tout comme Linux, ce système sera libre et gratuit.
Système de contrôle de version (VCS)
Git est donc un système de contrôle de version, il permet tout simplement de suivre l’évolution du code au fil du temps, à l’aide de branche, de fichiers et d’opérations sur ces fichiers.
Git est structuré comme suit :
- on y retrouve des fichiers (le code source)
- des branches (correspondant à une arborescence de fichiers)
- et des opérations pour faire évoluer les fichiers dans les branches
Grâce à ces opérations, git permet de savoir qui a touché à quel fichier, à quel moment et comment.
GitHub, GitLab, Bitbucket, etc.
Git est un logiciel qui permet de sauvegarder et de gérer localement l’évolution du code source au fil du temps. GitHub, GitLab, Bitbucket, etc. sont des plateformes (web) qui se servent du logiciel git pour gérer le code source. Les dépôts ne sont alors plus gérer localement mais sur des serveurs distants et permettent donc notamment la collaboration avec plusieurs personnes. Ces plateformes proposent également de nombreuses fonctionnalités de gestion de projets et d’équipes (wiki, affectations de tâches, suivi des problèmes, roadmap, statistiques, etc.).
Les bases
Git Flow
Git Flow est une organisation de travail basé sur la capacité de Git à gérer des branches. Par défaut il existe une branche principale qui s’appelle main (anecdote : anciennement master, ce nom par défaut a changé pour des raisons culturelles, ne plus assimiler la notion de master/slave à l’industrie du développement face aux nombreux cas de racisme dans le monde). Il existe une deuxième branche que nous allons créer et qui sera également considérée comme principale, il s’agit de la branche develop.
Nous avons donc 2 branches principales :
- main (anciennement master), qui représente le code source utilisé sur la production
- develop, qui contient les dernières fonctionnalités dont la phase de développement est terminée
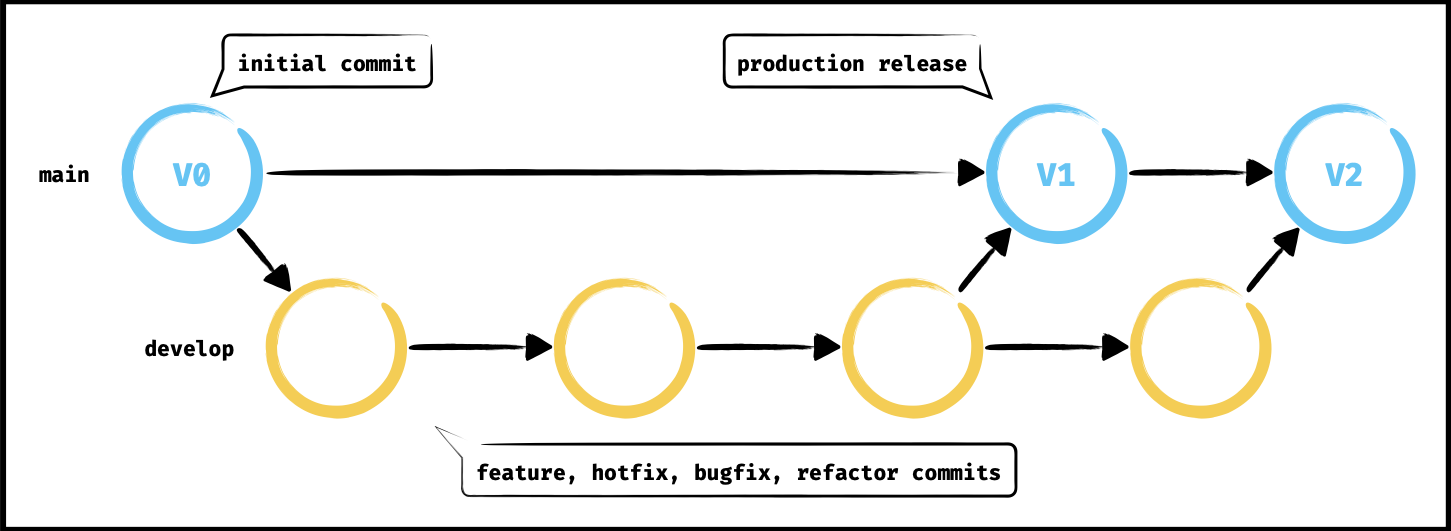
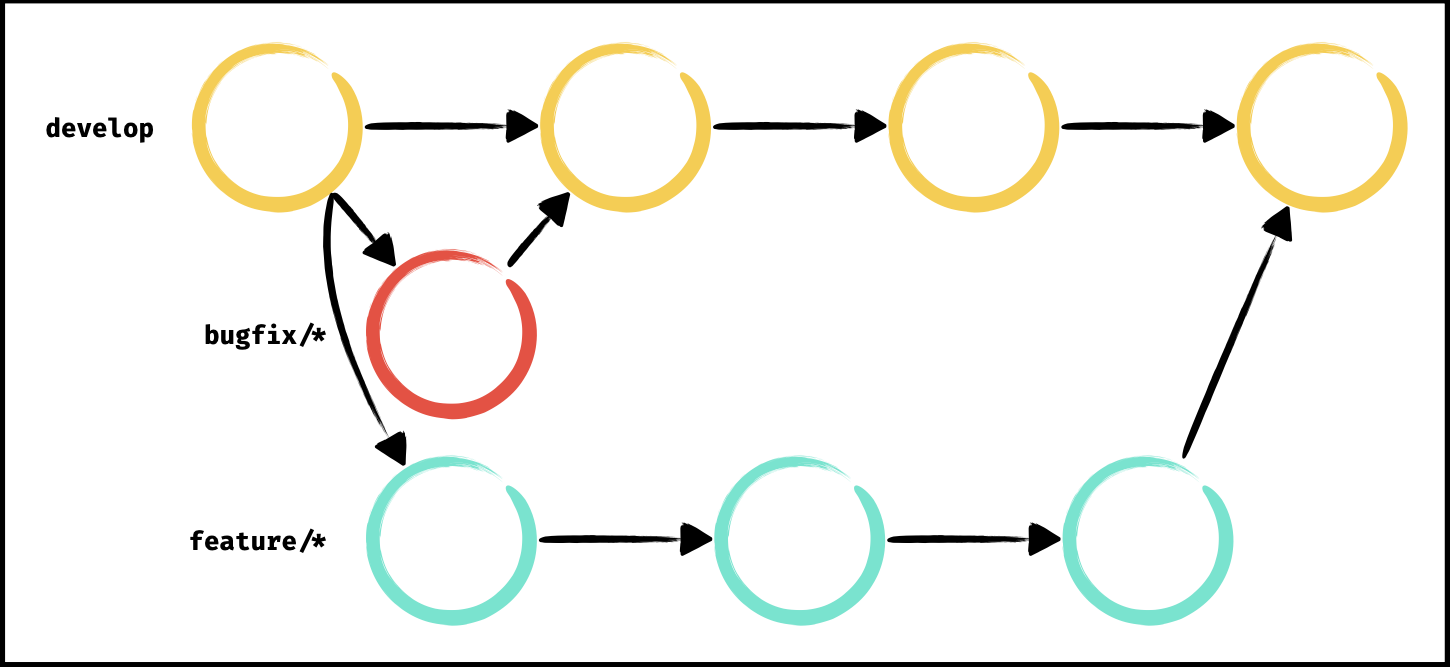
Tout au long du développement du projet, de nombreuses branches seront créées lors du développement des fonctionnalités et des corrections diverses. Ces branches respecteront des conventions de nommages comme suit :
- feature/*, pour les branches de fonctionnalités
- hotfix/* ou bugfix/*, pour les branches de corrections
- refactor/*, pour améliorer la qualité du code
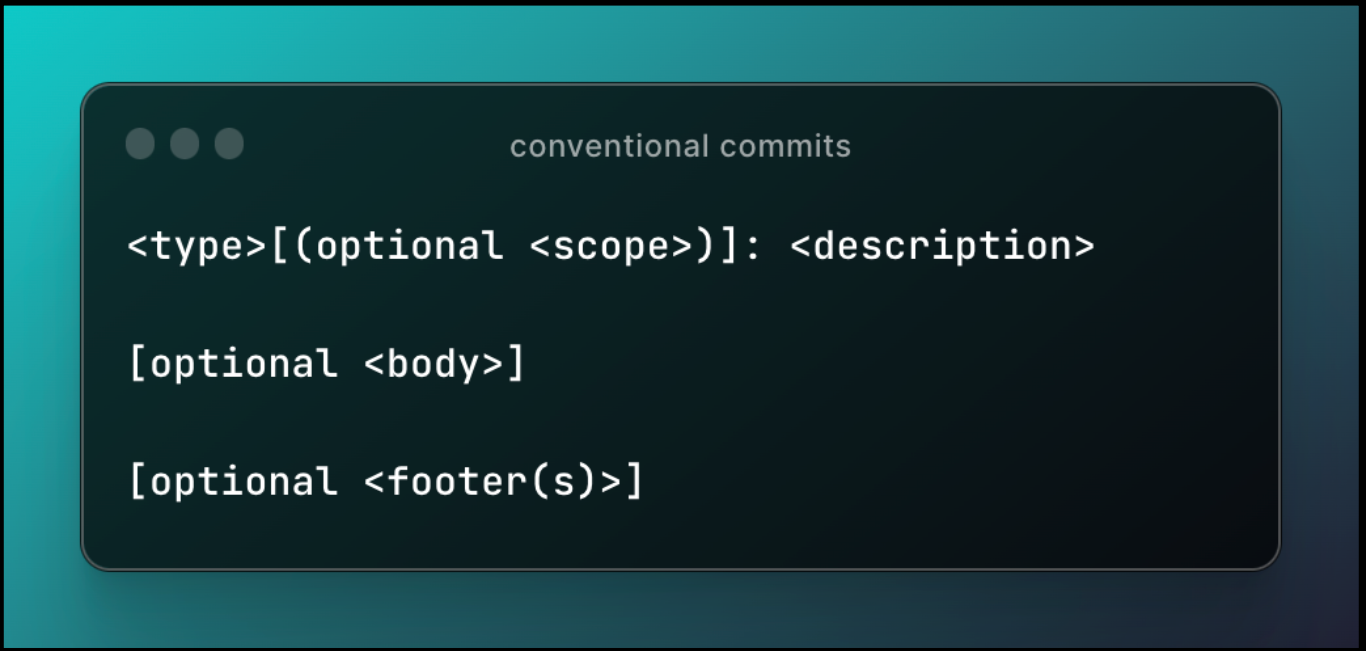
Conventional Commits
Conventional Commits est une spécification dont le but est d’améliorer la lisibilité des commits et l’historique des modifications du code source. À l’aide de ces conventions on peut identifier immédiatement le type, le contexte et l’objectif des modifications apportées au code sur un commit (nota bene : Cela permet aussi d’être compris par des outils automatisé pour générer de la documentation en autres).
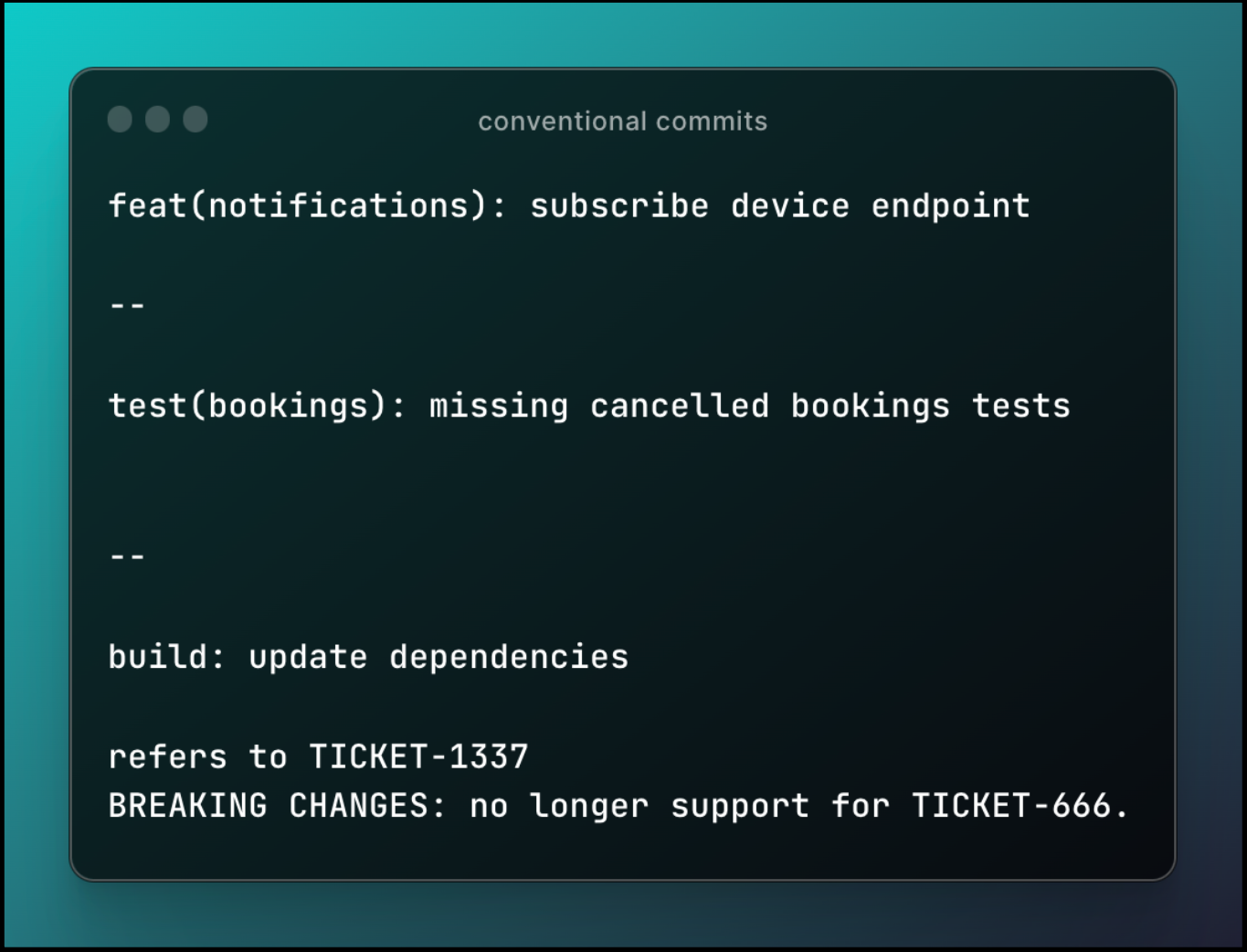
Les types de commits les plus utilisés sont :
- feat, développement d’une feature
- fix, correction d’un bug
- refactor, amélioration du code
- test, ajout ou mise à jour de tests
- chore, tâche technique non assimilée à une feature
- remove, revert, style, ci, docs, etc.
Workflow : merge vs rebase
Avec Git Flow on travaille donc sur des branches partant de develop (ou autre) et une fois le travail terminé on met à jour develop pour qu’il ai connaissance des modifications apportées.
Il existe plusieurs façons de ramener les modifications d’une branche vers une autre. On peut utiliser la politique de merge ou bien la politique de rebase. Ces deux méthodes ont des avantages et des inconvénients.
Politique de merge
Lorsque le travail de développement est terminé sur une branche (de feature, de refactor, etc.), la branche contient un certain nombre d’opération qui n’existent pas sur la branche d’origine. Le principe de la politique de merge est simple : récupérer les modifications faites sur une branche et les ramener sur une autre branche qui n’a pas connaissance de ces modifications. Ces modifications sont ramenées telles quelles.
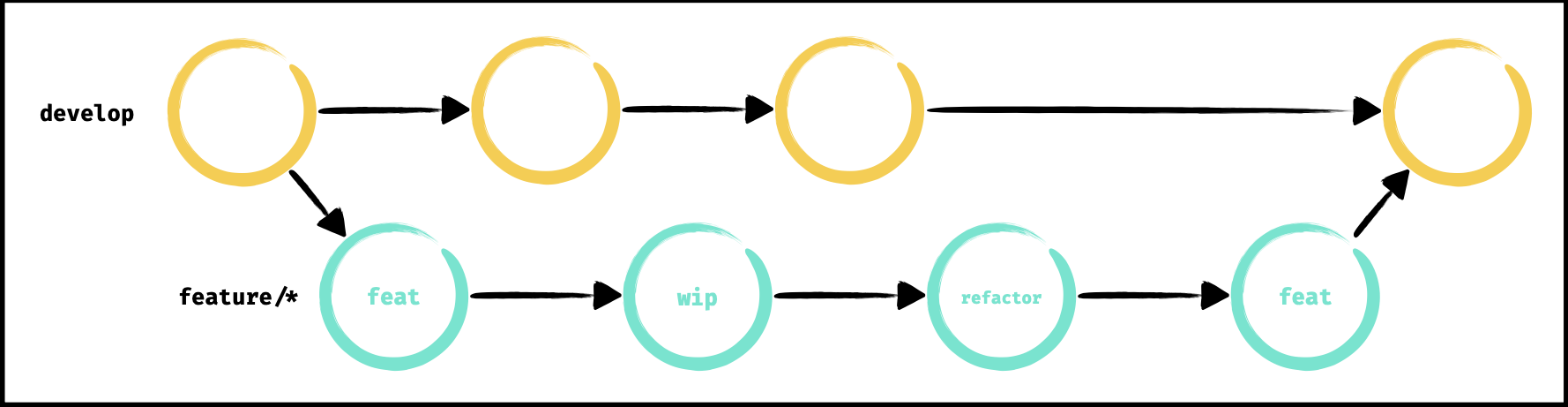
Avantages :
- traçabilité totale, l’historique du code source correspond totalement à ce qui a été fait
- résolution des conflits en une seule fois (peut être un inconvénient dans certains cas)
Inconvénients :
- historique du code source vite pollué par des opérations inutiles “wip” ou des opérations qui s’annulent
- historique peu fiable et difficile à debugger
- résolution des conflits en une seule fois (peut être un avantage dans certains cas)
Politique de rebase
Lorsque le travail de développement est terminé sur une branche (de feature, de refactor, etc.), la branche a donc un certain nombre d’opération qui diverge de la branche principale. Lorsqu’on suit une politique de rebase, notre objectif va être de nettoyer ces opérations en les réécrivant jusqu’à avoir le nombre minimum d’opérations pertinentes.
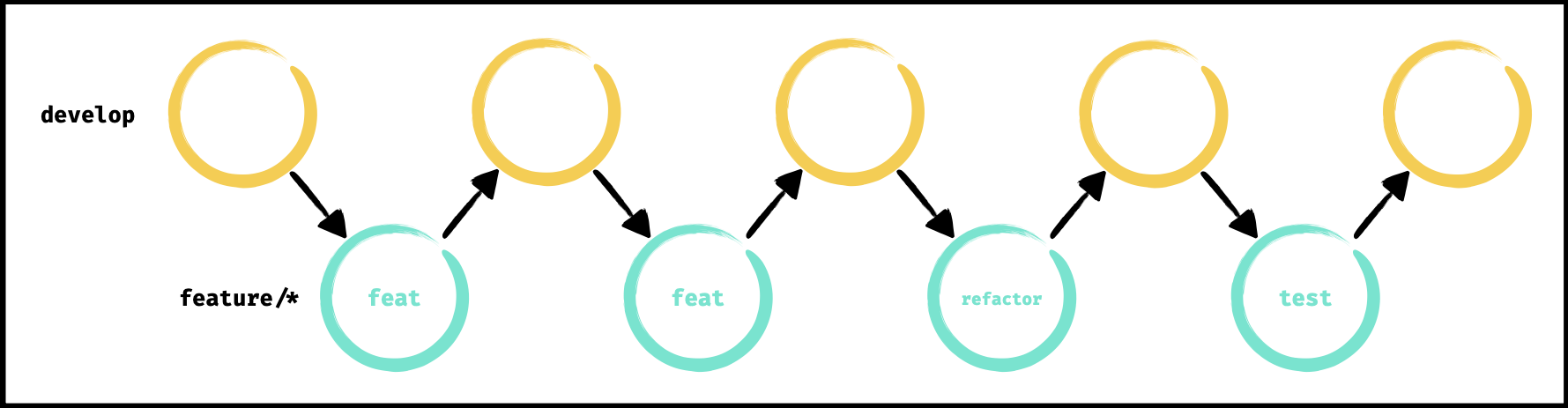
Avantages :
- historique du code source linéaire et lisible qui peut servir de documentation
- messages de commit clairs et respectant les conventions, plus de “wip”
- plus de commits qui s’annulent et donc une fiabilité de l’historique
- facilité pour revenir en arrière et trouver l’origin d’un bug car l’historique n’est pas pollué
- facilité pour revoir une feature complète, pour la modifier ou l’annuler
- résolution des conflits opération par opération (peut être un inconvénient dans certains cas)
Inconvénients :
- demande une grande rigueur car on réécrit en permanence l’historique
- demande une bonne communication ou des règles précises si on travaille en équipe sur la même branche
- la réduction d’une nombre d’opération au minimum est parfois trop extrême et atténue la clarté du contexte dans certains cas
- résolution des conflits opération par opération (peut être un avantage dans certains cas)
Nettoyage avec rebase Interactif
Avec la politique de rebase on réécrit l’historique des opérations faites sur le code source. Pour cela on peut utiliser des outils comme GitKraken ou autre, mais on peut également utiliser la commande git rebase interactive.
Les rebases réécrivent l’historique et donc écrasent totalement ce qui existait avant. En équipe il est donc indispensable de bien communiquer, de bien se mettre à jour et de prendre le soin de ne pas travailler sur la même branche. Si ces règles ne sont pas respecter, les pertes de code sont plus que probables !
Le processus classique de développement pour ne pas rencontrer de problèmes et profiter de la puissance du rebase est le suivant (en plus :
- travailler en local en faisant autant d’opérations que nécessaires
- lorsque le travail est terminé et que tout fonctionne comme il faut, créer une pull request et demander une revue de code en gardant l’historique de code tel qu’il est pour garder du contexte et donner à l’auteur de la revue de code un moyen de comprendre le cheminement de pensé qui a amené à ces modifications
- une fois la revue de code terminée et acceptée, il faut utiliser le rebase interactive pour nettoyer le code et ne garder que les opérations nécessaires
- intégrer les modifications sur la branche d’origine et supprimer la branche créée précédemment
🧑💻 Démonstration
Supposons nous avons un dépôt git avec une seule branche main et un seul fichier hello.ts qui contient une fonction “Hello World !” comme suit :
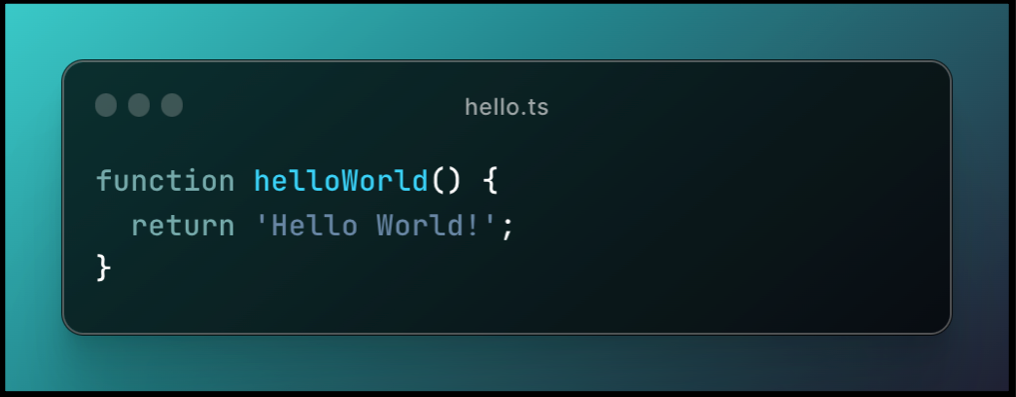
Maintenant, nous devons développer la fonctionnalité “Good Bye World!”.
Pour cela, nous allons donc commencer par créer une branche qui respecte les conventions de nommage : git checkout -b feature/good-bye
Puis, nous allons créer un fichier good-bye.ts et écrire la fonction suivante :

Et nous allons créer un commit contenant cette fonctionnalité : git commit -m “feat: good bye world”.
Vous l’avez peut-être remarqué, une erreur s’est glissée dans la fonction, nous allons donc faire un commit pour la corriger :
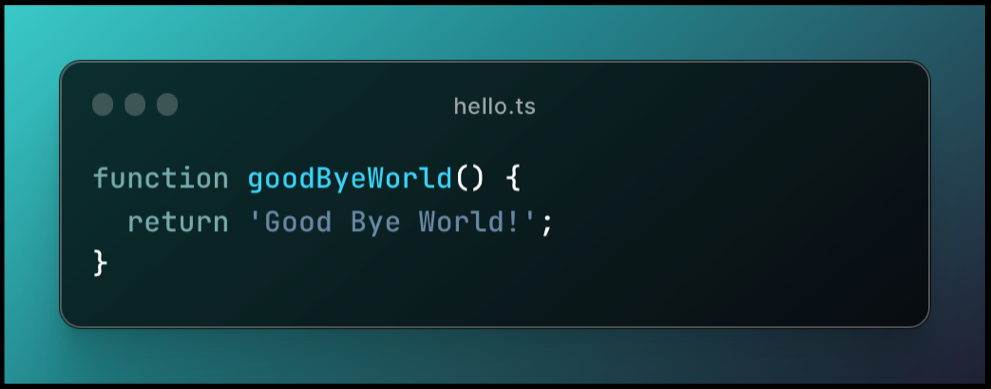
Avec le commit suivant : git commit -m “fix(good-bye): typo”.
Nous avons donc 2 commits alors qu’il serait plus pertinent d’en avoir qu’un seul. Nous allons donc utiliser le git rebase interactive pour réécrire l’historique des modifications.
Pour initialiser le rebase interactive on utilise la commande suivante : git rebase interactive HEAD~2
Cette commande va ouvrir l’interface suivante :
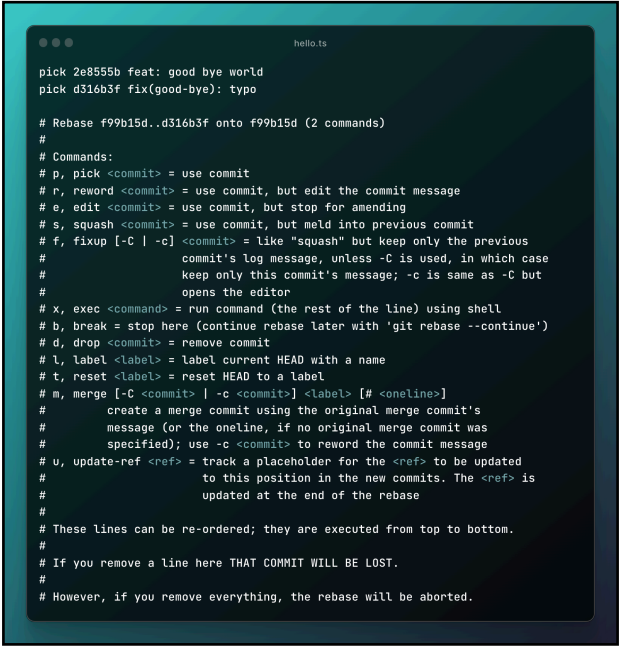
Sur cette interface on voit les 2 derniers commits de mon dépôt git (parce qu’on a utilisé HEAD~2). On y retrouve également une documentation des commandes qu’on peut utiliser devant l’identifiant de chaque commit.
Dans notre cas, on veut fusionner les modifications du deuxième commit avec le premier commit. C’est donc la commande fixup qui nous intéresse, nous allons donc remplacer pick devant le commit fix(good-bye): typo par fixup.
On enregistre et on obtient l’historique suivant (un seul commit) :
7f077f4 (HEAD -> feature/good-bye-world) feat: good bye world
Liens utiles
- https://wikipedia.org/wiki/Linus_Torvalds
- https://wikipedia.org/wiki/BitKeeper
- https://wikipedia.org/wiki/Git
- https://git-scm.com/book/
- https://nvie.com/posts/a-successful-git-branching-model/
- https://www.conventionalcommits.org/en/v1.0.0/
- https://ray.so
- https://www.atlassian.com/git/articles/git-team-workflows-merge-or-rebase
