

Julien
Head of Mobile
Mobile
L’essor des applications mobiles sur le marché
Les applications mobiles transforment l'engagement client, avec des hausses allant jusqu'à 25% dans la fidélisation et 20% dans les conversions, propulsées par des interfaces utilisateurs intuitives et des fonctionnalités innovantes.
Articles de Julien

Migration d'app native vers React Native ou Flutter : retour d'expérience
Pourquoi et comment migrer une app native iOS/Android vers React Native ou Flutter. Stratégie progressive, critères de choix, checklist et résultats concrets.

Architecture Hexagonale : construire une application Web & Mobile moderne, maintenable et orientée métier
Découvrez l'architecture hexagonale : principes, exemples, intégration avec Spring Boot. Optimisez votre code pour des applications mobiles robustes.

2FA, biométrie, SSO : quelles sont les meilleures pratiques de sécurité pour une app B2B ?
Dans cet article, on partage ce qu’on applique sur nos produits B2B : comment faire de la sécurité une expérience fluide, sans renoncer à la rigueur ni à la conformité.

React Native en 2025 : encore la meilleure option pour développer une app cross-platform ?
Chez Yield, on voit la question revenir à chaque cadrage d’application : santé, RH, mobilité… Et la réponse n’est plus idéologique : elle dépend du type de produit, de l’équipe, et de la trajectoire qu’on veut donner à l’app.
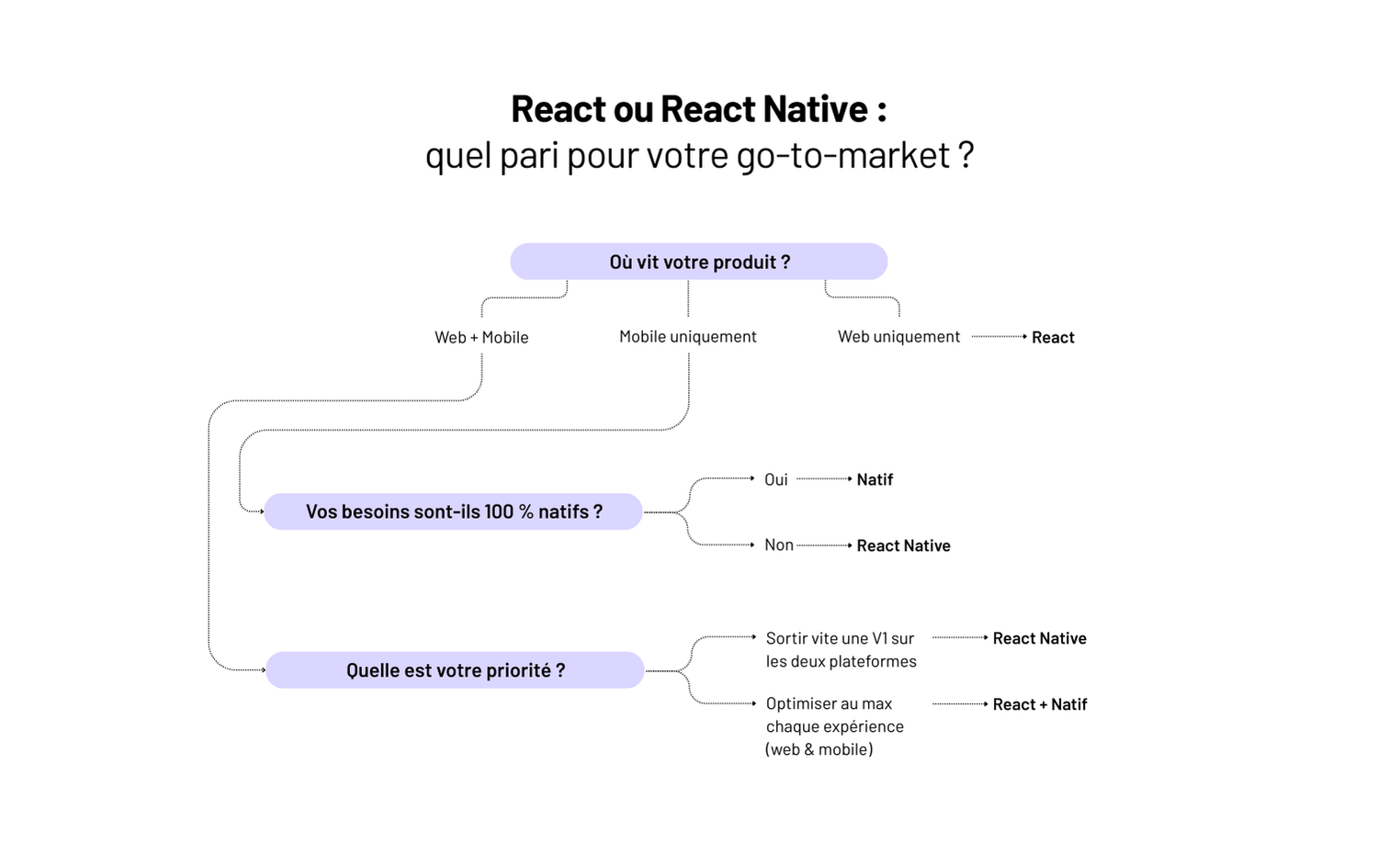
React vs react native : que choisir ?
Beaucoup pensent que React Native n’est qu’une extension mobile de React. En réalité, c’est un arbitrage stratégique !

Design Pattern : Compound Components
Nos composants traditionnels montrent parfois leurs limites. Ils ne sont pas tous adaptés pour faire face de manière flexible et robuste à l'évolution constante.

Trunk Based Development (TBD) vs Gitflow
La principale différence entre Gitflow et le TBD est que les premières branches ont une durée de vie plus longue et des commits plus importants.

Test Driven Development (TDD) : Guide pour un Développement Efficace
Découvrez le Test Driven Development : avantages, meilleures pratiques et impact sur la qualité du code. Maîtrisez l'art du TDD aujourd'hui !

Git : initiation, merge vs rebase, démo
Au délà de l'introduction à Git nous aborderons les sujets de base (Git flow, Conventional commits, ...) et la thématique de merge vs rebase afin de vous aider à cerner les différences.